To już ostatni materiał z książki dotyczący JPA jako takiego. Temat jednak dość istotny, zwłaszcza w różnego typu legacy-systems, których model danych potrafi być delikatnie mówiąc – zagmatwany. Napiszę dziś o dziedziczeniu encji.
Podstawy
Encje jako takie są zwykłymi klasami Javy. Tym samym jak najbardziej mogą rozszerzać inne klasy, a także być rozszerzane. Model obiektowy pozwala bardzo efektywnie przedstawić złożoność rozwiązywanych problemów biznesowych poprzez sensowne zastosowanie dziedziczenia. Z drugiej zaś strony mamy relacyjną bazę danych, która opiera się o tabele i relacje. Nie za wiele wie ona o dziedziczeniu. Istnieje kilka sposobów na rozwiązanie tego problemu.
Podstawowym pojęciem przy dziedziczeniu encji jest mapped superclass. Jest to klasa oznaczona adnotacją @MappedSuperclass. Oznaczenie nią encji spowoduje, że jej własności i relacje zostaną odzwierciedlone w encjach dziedziczących po tej klasie (i nie chodzi o same pola Javy, ale o rozpoznanie tego faktu przez JPA). Jednakże klasa taka sama w sobie nie posiada oddzielnej tabeli w bazie danych! Klasa taka nie musi być również deklarowana jako abstrakcyjna, jednakże jest to dobra praktyka – klasa taka nie powinna mieć instancji – powinna być reprezentowana tylko i wyłącznie przez klasy dziedziczące po niej. Klasy oznaczone tą adnotacją nie mogą również być używane do wyszukiwania oraz w zapytaniach (np. jPQL). Służą tylko jako opakowanie podstawowych własności w jednym miejscu, tak by klasy po niej dziedziczące zawierały tylko specyficzne siebie pola czy zachowania.
Należy wspomnieć, że same encje też mogą być abstrakcyjne. Możemy ich normalnie używać w aplikacji, jedynie nie możemy fizycznie tworzyć ich instancji, ale mogą bez problemu służyć jako typ obiektu, który po nich dziedziczy.Zanim przejdę do przykładów kodu dodam jeszcze, że dziedziczenie przez encje po zwykłych klasach Javy jest oczywiście możliwe. Te zwykłe klasy nazywa się transient-classes – oczywiście dziedziczy się po nich zachowanie oraz stan, ale nie są one odzwierciedlane w bazie danych.
Poznaliśmy już adnotację @MappedSuperclass. Wspomniałem również, iż nie posiadają one swojej reprezentacji w bazie danych (w formie tabeli). Dlatego też za podstawę ‘bazodanową’ dziedziczenia uznaje się klasę będącą encją. Może ona rozszerzać klasy oznaczone @MappedSuperclass, ale oczywiście nie musi. W specyfikacji JPA zostały przedstawione trzy strategie realizacji dziedziczenia po stronie bazy danych. Są to Single-Table Strategy, Joined Strategy oraz przedstawiona, ale niewymagana do implementacji przez dostawców Table-per-Concrete-Class Strategy. Przedstawię je poniżej opierając się na przykładzie encji broni, którą może używać bohater w naszej wzorcowej implementacji gry RPG. Do tej pory broń była reprezentowana przez jedną encję – Weapon. Dziś dodamy trochę urozmaicenia.
Single-Table Strategy
Zgodnie z nazwą dziedziczenie jest realizowane w oparciu o jedną tabelę w bazie danych. Automatycznie implikuje to istnienie w niej kolumn, które będą w stanie przechować stan wszystkich encji, które realizują dziedziczenie w oparciu o tę metodę. Przerobimy zatem naszą encję reprezentującą broń na trzy encje, które będą reprezentowały różne typy broni.
@Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="WEAPON_TYPE",discriminatorType=DiscriminatorType.STRING)
public abstract class Weapon {
@Id
@GeneratedValue(generator="increment")
@GenericGenerator(name="increment", strategy = "increment")
private Long id;
private String name;
// Getterki i setterki ominiete
}
@Entity
@DiscriminatorValue("StingWeaponDiscValue")
public class StingWeapon extends Weapon {
private int stingAttack;
// Getterki i setterki ominiete
}
@Entity
@DiscriminatorValue("RangeWeaponDiscValue")
public class RangeWeapon extends Weapon {
private int rangeAttack;
// Getterki i setterki ominiete
}
Jak widać trochę się tutaj dzieje. Zaczniemy od encji Weapon – jest to klasa abstrakcyjna, która jednakże zostanie odwzorowana na tabelę, gdyż posiada adnotację @Entity. Jest ona również oznaczona adnotacją @Inheritance, która pozwala określić typ użytej strategii dziedziczenia. Jeżeli adnotacja ta nie zostanie użyta, albo też nie zostanie podany typ strategii, wówczas zostanie zastosowany domyślny typ czyli właśnie Single-Table Strategy. By jednak pokazać możliwości tej adnotacji w powyższym przykładzie podałem wartość tego atrybutu. Użyta została też adnotacja @DiscriminatorColumn. Określa ona nazwę kolumny w tabeli, w której będzie przechowywana informacja o klasie, która ma zostać użyta do stworzenia instancji encji. Podajemy też typ kolumny – domyślnie jest to podana przeze mnie wartość STRING, ale możliwe są też INTEGER oraz CHAR.
Poszczególne klasy dziedziczące po encji broni są dość proste – dodajemy tylko jedną własność określającą wartość punktową zadawanego ataku. Jedyną nowością jest dodanie adnotacji @DiscriminatorValue, której znaczenie jest dość oczywiste. W przypadku jej braku dostawca JPA użyje nazwy klasy. To wszystko. Teraz w kodzie aplikacji możemy stworzyć takie cos:
entityManager.getTransaction().begin();
StingWeapon sword = new StingWeapon();
sword.setName("Super-Duper-Miecz");
sword.setStingAttack(10);
entityManager.persist(sword);
RangeWeapon bow = new RangeWeapon();
bow.setName("Super-Duper-Dlugi-Luk");
bow.setRangeAttack(10);
entityManager.persist(bow);
entityManager.getTransaction().commit();
W bazie danych po uruchomieniu powyższego otrzymamy taki efekt:
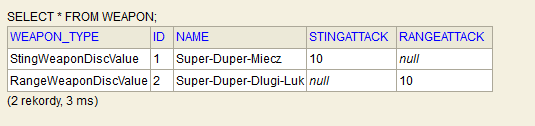
Jak widać niewykorzystane kolumny zostały wypełnione wartościami NULL. Kolumna zawierająca informacje o typie klasy została wypełniona automatycznie wartościami, które określiliśmy w definicji encji. Wszystko pięknie działa 😉
Joined Strategy
Zastosowanie strategii jednej tabeli może być na dłuższą metę dość zasobożerne. Nagle okazuje się, że w przypadku rozbudowanych hierarchii nasza tabela zawiera dużą ilość kolumn, które w znacznej mierze zawierają wartości NULL. Jeżeli nasza hierarchia dziedziczenia będzie dość rozbudowana można zastosować inną strategię – joined strategy. Wykorzysta ona siłę współczesnych baz danych – relacje. W przypadku naszego kodu wystarczy, że zmienimy wartości w adnotacjach, aby stworzyć podstawową tabelę z bronią (klasa Weapon), zaś dodatkowe informacje przechowywane w każdej z klas zostaną zapisane w oddzielnych tabelach.
@Entity
@Inheritance(strategy=InheritanceType.JOINED)
@DiscriminatorColumn(name="WEAPON_TYPE",discriminatorType=DiscriminatorType.STRING)
public abstract class Weapon { ... }
I ponowne uruchomienie naszego kodu spowoduje utworzenie 3 różnych tabel:

O dziwo nie zostały wygenerowane kolumny rozróżniające, ale taki kod działa:
entityManager.getTransaction().begin();
RangeWeapon bowNew = (RangeWeapon) entityManager.find(Weapon.class,2L);
System.out.println("Range attack: " + bowNew.getRangeAttack() );
System.out.println("Name: " + bowNew.getName());
entityManager.getTransaction().commit();
W konsoli (po uprzednim wyczyszczeniu persistence-context) generowane jest takie zapytanie SQL:
select weapon0_.id as id1_10_0_, weapon0_.name as name2_10_0_, weapon0_1_.rangeAttack as rangeAtt1_8_0_, weapon0_2_.stingAttack as stingAtt1_9_0_, case when weapon0_1_.id is not null then 1 when weapon0_2_.id is not null then 2 when weapon0_.id is not null then 0 end as clazz_0_ from Weapon weapon0_ left outer join RangeWeapon weapon0_1_ on weapon0_.id=weapon0_1_.id left outer join StingWeapon weapon0_2_ on weapon0_.id=weapon0_2_.id where weapon0_.id=?
Co wiele mówi o wydajności zapytań w przypadku używania tego typu strategii. Jednakże jeśli łatwość odwzorowania modelu oraz porządek logiczny w bazie danych jest dość istotny wówczas jest to rozwiązanie warte rozważenia.
Table-per-Concrete-Class Strategy
Jest to strategia, która niekoniecznie musi być zaimplementowana przez naszego dostawcę. Jej znaczenie jest w sumie proste – każda klasa w hierarchii dziedziczenia otrzymuje swoją własną tabelę. Po zmianie wartości adnotacji @Inheritance na InheritanceType.TABLE_PER_CLASS nasz kod po uruchomieniu spowoduje wygenerowanie ponownie 3 tabel, ale wyglądających tak:
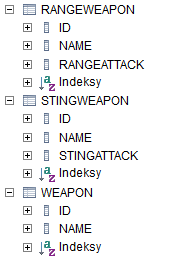
Zatem w bazie będą występowały informacje w sposób zdublowany. Jednakże rozwiązanie takie jest o wiele szybsze niż strategia relacyjna – zapytanie wybierające rekordy jest kierowane od razu do konkretnej tabeli, z pominięciem złączeń. Zatem o ile miejsce zajmowane przez dane nie jest istotne, albo też dane w bazie są prawie niezmienne, zaś często odpytywane warto zwrócić uwagę na tę strategię.
Próbując odpowiedzieć sobie na pytanie, która strategia jest ‘najlepsza’, odpowiedź będzie prosta – to zależy. Dość ciekawą dyskusję w tym temacie można znaleźć w wątku na GoldenLine.

 Spring to słowo-wytrych w świecie Javy. Pojawia się w olbrzymiej ilości projektów, w ogłoszeniach o pracę, sporo technologii ocenia się porównując je właśnie do Springa. Powiedziałbym, że czasem boję się otworzyć lodówkę…
Spring to słowo-wytrych w świecie Javy. Pojawia się w olbrzymiej ilości projektów, w ogłoszeniach o pracę, sporo technologii ocenia się porównując je właśnie do Springa. Powiedziałbym, że czasem boję się otworzyć lodówkę…


